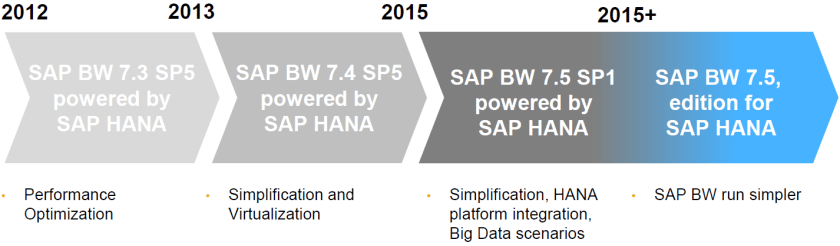
SAP BusinessObjects Cloud es la plataforma SaaS (Software as a Service) de SAP para el Business Intelligence y planificación, en algún momento se denominaba SAP Cloud for Analytics, pero al ampliarse funcionalidades, SAP encontró el pretexto para cambiarle el nombre. Esta propuesta SaaS se base sobre la plataforma SAP HANA Cloud.
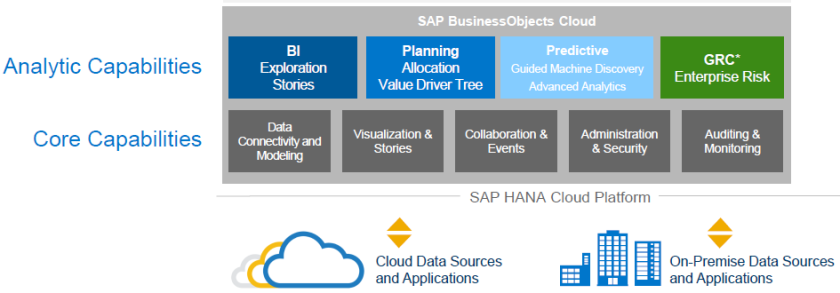
Dependiendo la suscripción contratada, se puede disponer de las siguientes aplicaciones:
- SAP BusinessObjects Cloud for Business Intelligence
- SAP BusinessObjects Cloud for Planning
- SAP BusinessObjects Cloud for Predictive Analytics
- SAP BusinessObjects Cloud for Governance, Risk and Compliance (GRC).
Actualmente SAP BO Cloud tiene las siguientes capacidades:
- Conectividad en tiempo real. Acceso en tiempo real a fuentes SAP HANA (on-premise y cloud) a través del denominado “Live conecction”. A futuro se prevé acceso a BW y S/4HANA.
- Adquisición de datos. Replicación de datos en SAP BusinessObjects Cloud desde fuentes BW, Universos, SAP BPC NW, SAP BPC MS, ficheros planos, Salesforce.com y Google Drive.
- Visualización. Diseño de visualizaciones orientadas al negocio, personalización de pantallas, funcionalidades avanzadas de repoting y exportación a PDF.
- Colaboración. A través de la aplicación móvil se ofrece funciones de chat, visualización de eventos y tareas, gestión de notificaciones.
- Administración. Gestión de usuarios y equipos, Monitorización.
- Auditoria. Monitorización del rendimiento para un usuario o un modelo en cualquier período de tiempo.
Es posible contratar este servicio como una nube pública (multiple tenants) o nube privada, la diferencia se encuentra si se desea compartir recursos (no datos) con otros suscriptores o se desea unos recursos para uso exclusivo. Con recursos nos referimos a la capacidad y tiempo de procesamiento, memoria, aplicaciones y sistema operativo. En ambos casos se olvidaría de mantener las aplicaciones y la infraestructura que estas requieren, lo usual en una instalación clásica u on-premise.