SAP BW/4HANA es la, relativamente, nueva solución de data warehouse (liberado el 7 de septiembre 2016), a la que SAP dedicará sus mejores esfuerzos en el futuro. El fabricante señala que BW 4HANA no es el sucesor de soluciones actuales similares tales SAP BW o SAP BW powered by HANA o BW edition for HANA, dado que es una solución completamente construida sobre SAP HANA, la cual introduce nuevos objetos y descarta otros, inclusive cuenta con un nuevo Business Content.
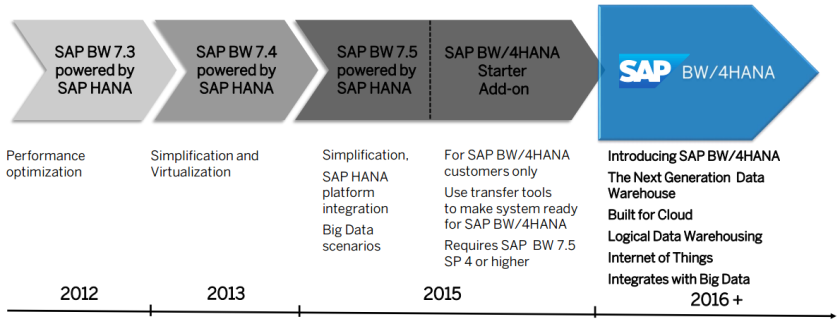
BW 4/HANA introduce, a través de nuevas interfaces de usuario, una nueva gama de objetos para el modelado de datos que cubran necesidades tales como acceso en tiempo real a grandes volúmenes de información.
¿Qué pasará con las actuales soluciones BW de SAP?
La solución clásica de SAP NW BW o las más recientes, basadas en HANA, denominadas con los sufijos ON HANA o powered by HANA entrarán en fase de mantenimiento, con innovaciones mínimas, las más relevantes innovaciones se darán en BW/4HANA, solución que será independiente de la plataforma SAP NetWeaver.
¿Qué relación tiene BW/4HANA con S/4HANA?
El término “/4” puede inducir a creer que existe una relación entre ambos productos, pues esto no es así, se trata de dos productos totalmente independientes uno del otro. Tampoco se solapan, dado que la filosofía, ámbito y alcance de ambas plataformas es distinta. S/4 HANA es una plataforma transaccional que brinda la posibilidad de obtener informes operativos de los datos actuales de una única aplicación SAP.
BW/4HANA es una plataforma data warehouse que permite consolidar información actual e histórica, de diversas fuentes, SAP y no SAP, con el fin de facilitar su explotación.
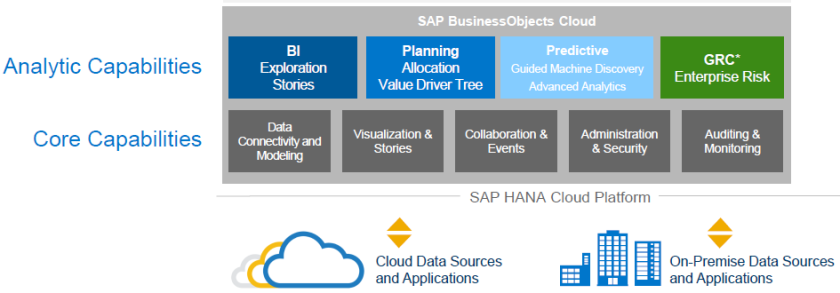
¿SAP BW/4HANA con qué herramientas analíticas es compatible?
SAP asegura compatibilidad SAP Digital Boardroom y SAP BusinessObjects Cloud. Así mismo asegura compatibilidad con la plataforma SAP BusinessObjects BI Enterprise la cual incluye a Lumira, Design Studio, Analysis for Office, Web Intelligence y Crystal Reports.
En cuanto a la plataforma BEx (Business Explorer), una vez más, parece que esta vez será así, SAP asegura que no será soportado. Las querys BEx seguirán siendo compatibles pero se deberá utilizar la herramienta SAP BW/4HANA Modeling Tools para mantenerlas.
Comentario final
Sí, la “vorágine innovadora” de SAP conlleva a que nuevas implementaciones sean obsoletas desde el momento en que se planifican. Pero resulta elevadamente arriesgado adoptar una plataforma con tan poco recorrido, cuyas mejoras e innovaciones se encuentran en curso, los mecanismos de migración son artesanales y la compatibilidad o equivalencia entre objetos, tal como señala el fabricante, es mínima.
Pero este riesgo, que en algunos casos se deberá asumir, tanto para nuevas implementaciones como implementaciones existentes que requieren una actualización, debe ser gestionado definiendo fases con criterio funcional, identificando con claridad la arquitectura de datos crítica en cada momento, determinando los elementos técnicos de BW4/HANA disponibles que requiere el modelo de datos identificado y minimizando desarrollos personalizados, dado lo que pueda faltar hoy, puede ser posteriormente agregado por el fabricante, por ejemplo, el denominado Business Content Optimizado recientemente ha agregado definiciones para FI, CO, MM y SD.