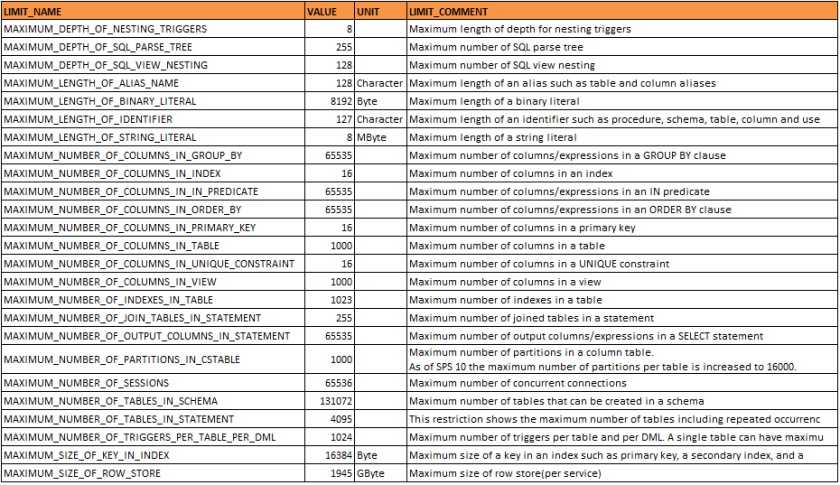
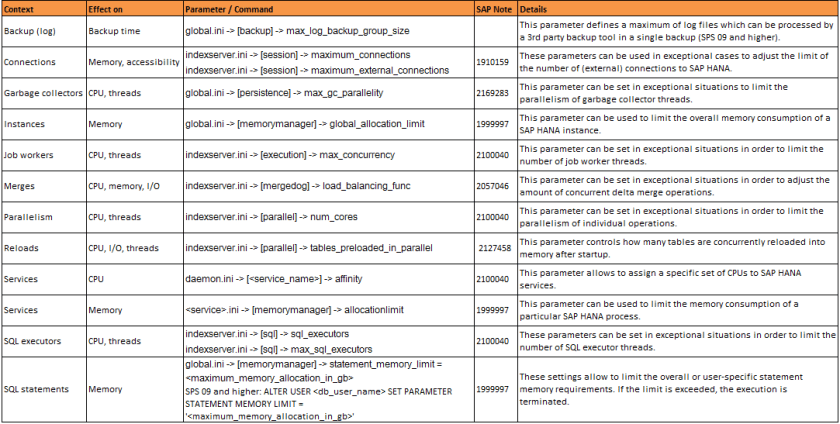
La actualización 4.2 y posteriores de la plataforma SAP BusinessObjects BI introduce dos características que podrían potenciar, aún más, el uso de SAP HANA como fuente de datos en los informes de Web Intelligence, para lo cual, es necesario contar con un nivel de actualización posterior a la SPS08 de la plataforma in-memory (Ref. SAP Note: 2210945). Nos referimos a las nuevas funcionalidades «Web Intelligence HANA Direct Access» (Acceso directo SAP HANA) y «Web Intelligence HANA Online» (Modo con conexión SAP HANA).

Acceso directo SAP HANA en WebI
- Consiste en acceder directamente a vistas calculadas o analíticas de SAP HANA Database a través de un universo temporal (transient universe).
- Este «universo temporal» se podría construir al vuelo desde la interfaz de Web Intelligence (versiones JAVA, HTML o Rich client) al seleccionar como fuente de datos una conexión relacional u OLAP a HANA, conexiones publicadas en el repositorio de la plataforma (conexión segura), la cual podría definirse desde la CMC o desde Information Design Tool (IDT).
- Dependiendo el tipo de conexión, relacional u OLAP, se generarán unos objetos u otros. Este universo temporal no es reutilizable.
- Lo bueno: facilidad y rapidez para utilizar modelos de datos existentes en HANA. Lo malo: La imposibilidad de reutilizar los universos temporales que se definan.
Conexión online SAP HANA en WebI
- Con la nueva opción SAP HANA Online (o SAP HANA Conectado) es posible conectarnos, a través de una conexión relacional, a vistas analíticas o calculadas de SAP HANA para delegar los cálculos y agregaciones a la base de datos de HANA.
- Al perder algunas funcionalidades de la interfaz de WebI, hay la posibilidad de pasar al modo clásico, pero no habría la posibilidad de volver al modo conectado.
- Si se accede a un importante volumen de datos o se realizan varios cálculos y agregaciones en las consultas de un informe contra fuentes HANA, esta nueva característica será muy útil.