SQLScript es una variante del lenguaje estándar SQL-92 (Structured Query Language), diseñado por SAP para obtener el máximo beneficio de un sistema de base de datos de SAP HANA. Tanto el SQL estándar, como SQLScript pueden ser usados en HANA. El SQL tradicional se puede utilizar para crear tablas de datos (cuando las estructuras de metadatos no pueden ser importadas). También se pueden utilizar SQL para crear vistas de cálculo (calculation views), para manipular los datos y gestionar transacciones.
SQLScript es una variante del lenguaje estándar SQL-92 (Structured Query Language), diseñado por SAP para obtener el máximo beneficio de un sistema de base de datos de SAP HANA. Tanto el SQL estándar, como SQLScript pueden ser usados en HANA. El SQL tradicional se puede utilizar para crear tablas de datos (cuando las estructuras de metadatos no pueden ser importadas). También se pueden utilizar SQL para crear vistas de cálculo (calculation views), para manipular los datos y gestionar transacciones.
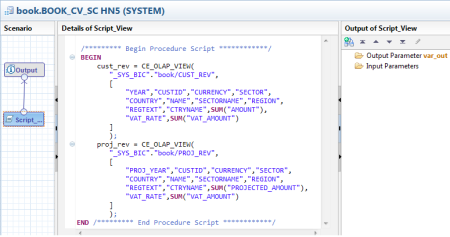
SQLScript está compuesto por un grupo extensiones (Data Extensions, Procedural Extensions y Functional Extensions) que contribuirán a que las operaciones con los datos se ejecuten sobre la base de datos HANA, utilizando de la mejor manera su arquitectura para obtener el máximo rendimiento del sistema. Para este fin, destacan las funciones CE:

Mensaje final: si estás escribiendo sentencias SQL en SAP HANA, siempre que puedas, utiliza la sintaxis de SQLScript para obtener el mejor rendimiento al acceder a la información.



