

Podríamos señalar que el cambio de nombres a los productos y/o a los componentes que lo conforman, es el paso inevitable por el que transcurre la gran mayoría de productos SAP hacia su maduración. Esta vez, le ha tocado al recientemente estrenado SAP Business Planning and Consolidation 10.1 para NetWeaver.
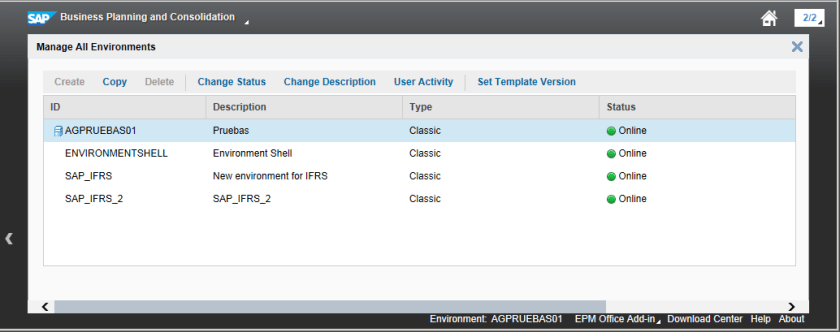
Tal como ya hemos comentado en alguna ocasión, en BPC 10.1 NW es posible crear entornos similares a los que conoces en la versión 10.0, a los que SAP nos enseñó, inicialmente, denominar como Clásicos (Classic). Por otro lado, en instalaciones de BPC 10.1 sobre SAP HANA, tenemos la posibilidad de crear estructuras para modelos de planificación que obtengan el máximo beneficio de la plataforma in-memory de SAP, esta otra categoría SAP nos indicó que se denominaba Unificado (Unified).
Pues bien, a través de la nota 2117885, SAP nos comunica que a partir del Support Package 3 (SP3) de BPC 10.1 NW, todo lo que conocíamos cómo Classic pasa a denominarse Standard y todo lo que conocíamos cómo Unified, ahora se denomina Embedded.
