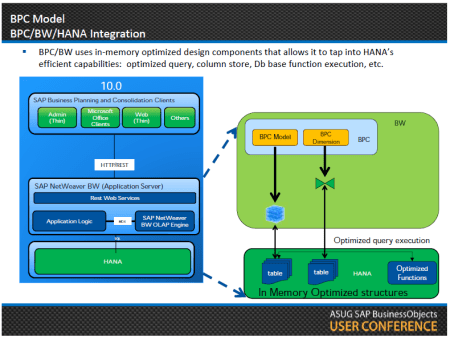
SAP HANA trabaja con información en tablas con almacenamiento en filas o en tablas con almacenamiento en columnas. Para procesar esta información existe un componente específico según cómo y qué se esté solicitando para obtener los mejores tiempos de respuesta.

Estos componentes se denominan motores (Engine):
- OLAP Engine. Procesa consultas analíticas básicas. Estas consultas se construyen a través de la definición de modelos físicos o lógicas (vistas analíticas) y se vinculan tablas construyendo una estructura denominada “esquema en estrella” (una o más tablas, que cumplen el papel de “dimensiones”, se vinculan a una o más tablas que cumplen el papel de “hechos”).
- Calculation Engine. Procesa las consultas complejas o los modelos lógicos diseñados en las vistas calculadas.
- Join Engine. Es el motor que procesa las sentencias SQL estándar como las que se pueden lograr construir a través de las vistas de atributos.
- Row Engine. Procesa consultas SQL más complejas, las que acceden a tablas con almacenamiento en filas o con lógicas recursivas.
Cada motor es especializado para cada tipo de estructura de datos, los rendimientos de cada uno de estos motores es distinto, por lo que el rendimiento global será la suma de todos los motores que interviene en un proceso. Por este motivo, es importante realizar el diseño más óptimo, tanto de las estructuras de datos como en las consultas o esquemas lógicos, para obtener los mejores tiempo de respuesta, SAP HANA, por sí sólo, no hace milagros.