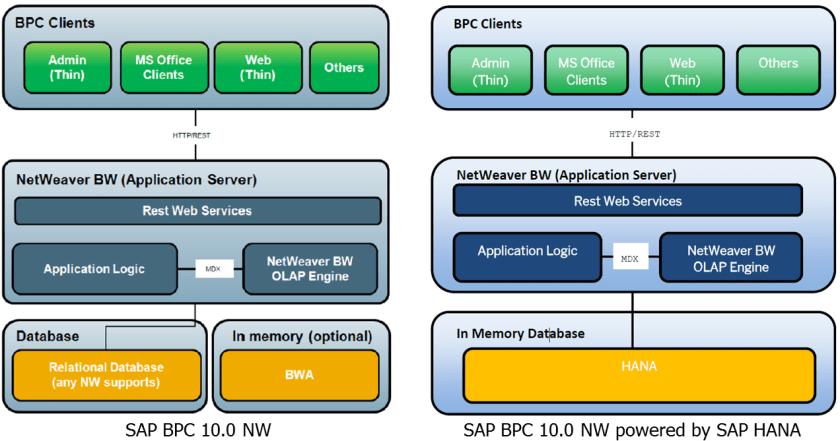
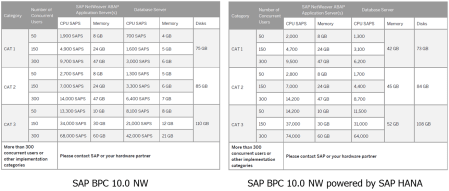
En SAP SCN encontramos un post que será muy útil para todos aquellos que estén comenzando a diseñar modelos de datos o a desarrollar aplicaciones en una plataforma SAP HANA. Por el momento se señalan seis “reglas de oro” que seguro se podrán ir ampliando en la medida que SAP HANA siga evolucionando al ritmo que lleva, presentando grandes cambios en cada actualización.
- Nunca utilices tablas con almacenamiento basado en filas. SAP HANA está preparado para trabajar con los dos tipos de almacenamiento de tablas (basado en filas y en columnas), el sistema ya cuenta con mecanismos necesarios para optimizar la grabación de datos en tablas con almacenamiento columnar. Una de las claves de éxito de HANA es el almacenamiento en columnas, son muy pocos los casos en que se recomienda las tablas con almacenamiento en filas, especialmente la tablas de parámetros o configuración.
- No crear índices. El almacenamiento columnar, equivale a tener un índice por cada columna, por lo que crear índices secundarios, tal como se estila hacer en un sistema de base de datos relacional tradicional, no ayuda a reducir los tiempos de acceso a los datos. Sólo podría ser útil en el caso de tener una tabla muy grande sobre la que se realiza una selección muy pequeña de un conjunto de datos.
- Utilizar la Perspectiva Development de SAP HANA Studio. SAP HANA Studio es la herramienta que facilita todas las tareas de administración y desarrollo en la plataforma HANA. Las capacidades que ofrece SAP HANA Studio están divididas en Perspectivas (véase como paneles o ventanas), dependiendo de las necesidades y autorizaciones disponibles se podrán habilitar las perspectivas. Para los desarrolladores se ofrecen varias perspectivas entre ellas System, Modeler y Debug, se sugiere el uso de la perspectiva Development, debidamente configurada se puede contar con todos los recursos necesarios en una única perspectiva.
- No utilizar SQLScript, a menos que sea necesario. SAP HANA ofrece una implementación SQL, la cual se denomina SQLScript, este lenguaje puede ser muy útil en determinadas circunstancias, pero en muchos casos lo que se realice con este lenguaje se podría hacer con vistas de información (de atributos, analíticas y de cálculos) las cuales son más eficientes dado que SQLScript no paraleliza la ejecución de procesos (hasta la reciente actualización SPS07 este es el comportamiento de SQLScript, quizás más adelante se ofrezca una actualización que mejore este comportamiento).
- Si utiliza SQLScript, no utilice cursores o SQL dinámico. El uso de estas sentencias ocasiona pérdida de rendimiento, especialmente el uso de SQL dinámico para referirse a nombres de columnas en sentencias INSERT o SELECT, hay otras alternativas disponibles, como las vistas de información (para los SELECTs) o el uso del lenguaje Python (para cargar datos).
- Evitar Joins en grandes volúmenes de datos. Unir tablas con más de cien mil filas resultará ineficiente, en su lugar se sugiere normalizar vía el uso de vistas analíticas, para luego unir vía una vista calculada.
Referencia: SAP SCN