La principal característica de SAP HANA es que los datos están almacenados en la memoria principal, lo que le permite procesar grandes volúmenes de información más rápido que las bases de datos tradicionales, las cuales, a menudo, deben recuperar los datos de la memoria secundaria (disco).
Por otro lado, SAP HANA potencia su capacidad de procesamiento en memoria aplicando otras técnicas, tales como:
- Gestión de datos en columnas (columnar)
- Compresión de datos
- Procesamiento en la capa de datos
- Particionamiento de tablas de bases de datos
Para que todo su software in-memory computing de HANA funcione según lo esperado, sólo utiliza un hardware con ciertas características, el cual es certificado por SAP (SAP HANA appliance), de este modo, se asegura que se cuenta con los recursos necesarios (memoria, disco, procesadores, etc).
Cabe señalar que el SAP HANA Appliance puede ser distribuido con uno de los siguientes sistemas operativos: “SUSE Linux Enterprise” o “Red Hat Enterprise Linux”. El appliance es optimizado a nivel de parámetros del sistema operativo y con el software HANA pre-instalado.
Escenarios SAP HANA
La plataforma SAP HANA brinda la posibilidad de desplegar los siguientes tipos de escenarios
Escenario Data Mart
Unos de los primeros enfoques que se dieron a conocer fue el de Data Mart, el cual se diseña a través de la replicación de datos y vistas HANA para que se exploten con herramientas analíticas, tales como SAP Lumira o Design Studio.
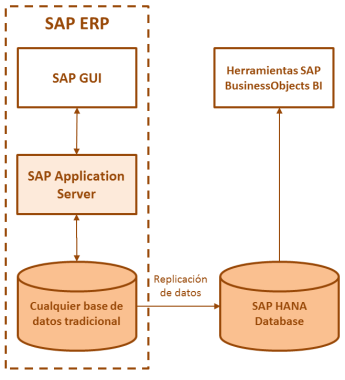
Escenario Accelerator
Por otro lado, tenemos el enfoque Acelerador, el cual también se basa en la replicación de datos, no para que estos datos sean evaluados con herramientas analíticas, sino para que transacciones o aplicaciones tradicionales adaptadas recuperen la información de SAP HANA database y no de la base de datos principal.
Un escenario Accelerator tiene como principal ventaja que se consigue mejorar el tiempo en las tareas de acceso a los datos sin necesariamente sustituir la base de datos. El aspecto más negativo, es que los datos se mantienen por duplicado y deben ser actualizados continuamente.
 Una de las primeras soluciones con el enfoque Acelerador ha sido CO-PA Accelerator, la cual aumenta la velocidad del análisis de la rentabilidad utilizando el módulo de Controlling del SAP ERP.
Una de las primeras soluciones con el enfoque Acelerador ha sido CO-PA Accelerator, la cual aumenta la velocidad del análisis de la rentabilidad utilizando el módulo de Controlling del SAP ERP.
Escenario Integrado
El enfoque integrado se diferencia de los anteriores en que SAP HANA no se ejecuta en paralelo con las bases de datos que se estuviesen utilizando, SAP HANA se integra totalmente a la arquitectura y reemplaza la antiguas bases de datos.
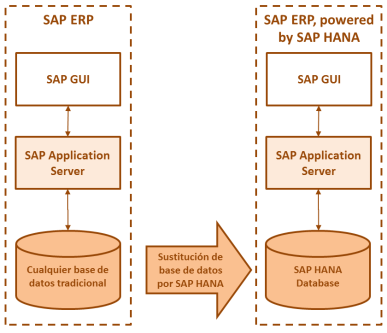
Una aplicación integrada se caracteriza por la transferencia de la lógica de aplicación a la capa de datos.
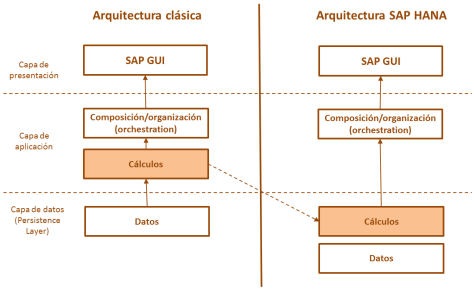 El enfoque integrado será posible sólo si las aplicaciones correspondientes se encuentran adaptadas y optimizadas para SAP HANA, lo cual significa que la base de datos, además de realizar las tareas de proveer y almacenar datos, es capaz de procesar o realizar los cálculos en la capa de datos (code push-down), dejándole a la capa de aplicación el papel de orquestación y desencadenante de complejas operaciones de cálculo. De este modo, la aplicación consume los
El enfoque integrado será posible sólo si las aplicaciones correspondientes se encuentran adaptadas y optimizadas para SAP HANA, lo cual significa que la base de datos, además de realizar las tareas de proveer y almacenar datos, es capaz de procesar o realizar los cálculos en la capa de datos (code push-down), dejándole a la capa de aplicación el papel de orquestación y desencadenante de complejas operaciones de cálculo. De este modo, la aplicación consume los
resultados en la capa de presentación. El más conocido representante en esta categoría es SAP BW on SAP HANA.