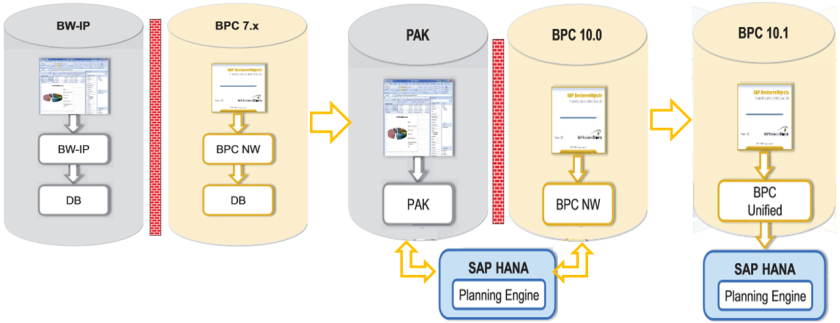
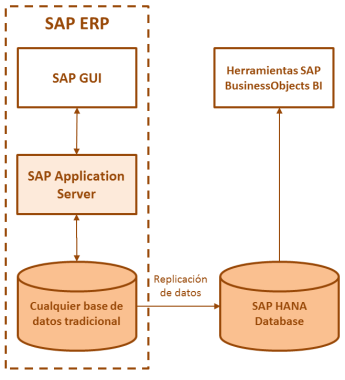
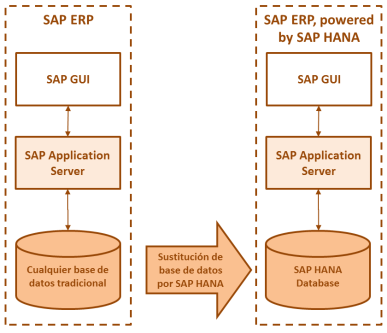
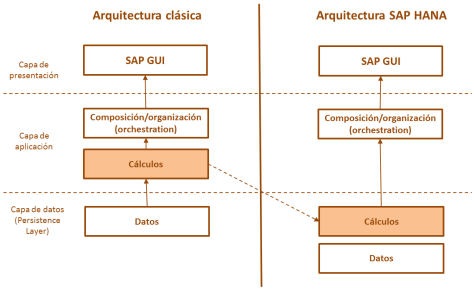
SAP S/4HANA es el acrónimo de SAP Business Suite 4 SAP HANA. S/4 es la nueva generación de Business Suite, llamado a ser el sucesor de SAP R/3. Se trata de un nuevo desarrollo, totalmente diseñado para la tecnología in-memory computing de SAP HANA.
S/4 pretende ser el referente para una nueva generación de aplicaciones, con una nueva interfaz de usuario, orientado a SAP Fiori y teniendo en consideración las tendencias actuales, tales como el Big Data, Internet de las cosas (Internet of Things – IoT) o movilidad.
Se ofrecerá bajo la modalidad on-premise (infraestructura propia), cloud e hibrida. Se podría utilizar la capacidad Multitenant (característica que consiste en definir más una base de datos en el mismo sistema), incluida desde la actualización SPS09 de SAP HANA.

Ediciones de S/4
- SAP S/4HANA, on-premise edition. Es de similares funcionalidades, idiomas, industrias que la actual Business Suite, además también incluye la simplificación que conlleva SAP Simple Finance.
- SAP S/4HANA, public cloud edition. Dirigido a específicos escenarios de líneas de negocio e industrias., se prevé almenos 10 escenarios básicos.
- SAP S/4HANA, managed cloud edition. Tendría un alcance similar a la edición on-Premise. La primera liberación ofrecería los escenarios básicos de un ERP (contabilidad, controlling, gestión de materiales, planificación y control de la producción, ventas y distribución, logística, mantenimiento, proyectos y PLM).
Integración
En todas las ediciones, se espera una integración futura con otros sistemas tales como SuccessFactors Employee Central (Plataforma de gestión integral de RRHH, incorporada al portfolio SAP desde fines de 2011) y Ariba Network (portal comercial B2B, que adquirió SAP en mayo de 2012).
Actualizaciones
La edición on-premise estará disponible para todas las industrias y regiones. En el caso de las ediciones cloud, su disponibilidad será progresiva durante el 2015. En cuanto a las actualizaciones y mejoras, SAP pondría a disposición una actualización anual para la edición on-premise y una actualización trimestral para las ediciones cloud.